SaySynth: A Brief History of Speaking Machines
These are expanded notes from a talk I gave at composition.codes on December 21, 2025. Slides here. Video here.
saysynth is a synthesizer I built on top of macOS’s text-to-speech framework — more popularly known as the say command. To explain why I built it and why I think it matters, I want to take a detour through the history of speaking machines more broadly.
A Typology of Speaking Machines
There are roughly four kinds of speaking machines that have existed over time:
Mechanical — Bellows forcing air through a reed, with different knobs, valves, and whistles shaping different formants and phonemes. The human operator is part of the instrument.
Formant/Rule-Based — More like a synthesizer: an oscillator and a comb filter simulating the resonant shape of the vocal tract. The system models the acoustics of speech without recording any actual speech.
Sample-Based (Concatenative) — From something as crude as a toy with a phonograph inside, all the way to sophisticated “diphone” synthesizers that splice together recordings of every possible phoneme transition. GPS voices and automated customer service phone lines of the ’90s and 2000s were built this way.
Generative (Neural/AI) — What most people think of today. These are basically sample-based systems taken to an extreme: instead of recordings of phoneme pairs, you’re dealing with individual digital samples predicted by a neural network, sample by sample.
A Brief History
Von Kempelen’s Speaking Machine (1773)
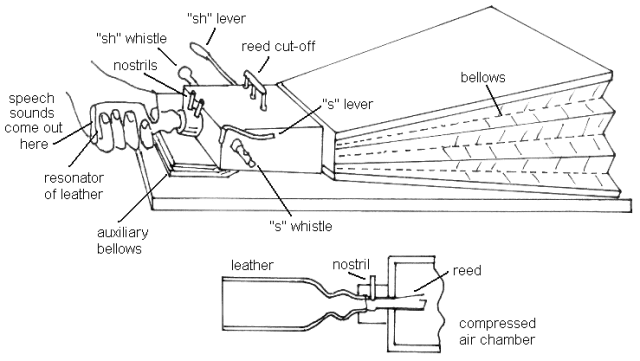
The first speaking machine most people point to. An operator pushes air through a reed and moves their hand around a piece of leather to simulate the shape of the vocal tract, while separate whistles handle noisier consonants like S and T. Crude, but the basic architecture — oscillator source, shaped by something simulating a vocal tract — is essentially what we still see in formant synthesizers today.
Joseph Faber’s Euphonia (1845)

Faber iterated on von Kempelen’s design into something far more sophisticated: sixteen keys, each generating a different phoneme. You can start to see the importance of the operator in these systems. To make it seem less threatening, Faber put a woman’s face on the front of it and, reportedly, sometimes hung a dress in front of the machinery. I suspect this had the opposite of its intended effect.
Edison Talking Dolls (1890s)
Not quite a speaking machine in the traditional sense, but the first concatenative one: a doll with a miniature phonograph inside playing back recordings of children’s rhymes. Edison thought embedding recorded voices in a toy would help people get comfortable with the technology.
VODER (1939)
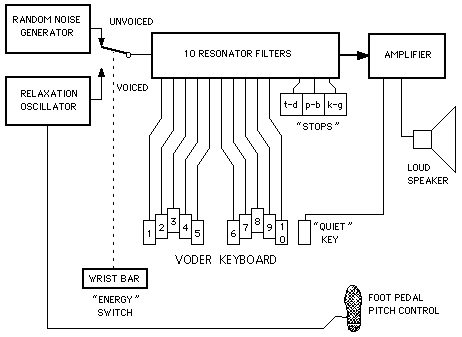
Demonstrated at the 1939 World’s Fair, the VODER was genuinely remarkable for its time — a monophonic synthesizer with an oscillator, a noise generator, and a set of controls for shaping phonemes in real time, with pitch controlled by a foot pedal. What I find most interesting about it is that its “impressiveness” was entirely dependent on its operators, women known as “Voderettes,” who trained for years to produce intelligible speech. The inventor got all the credit. The operators are largely nameless to history.
MUSA — Multichannel Speaking Automaton (1978)
Developed in Italy, MUSA was one of the first practical diphone synthesizers. They even pressed a vinyl record of the results. It uses recordings of every possible phoneme transition (around 2,000 combinations) and then applies DSP to smooth them together. This approach became dominant in commercial TTS through the ’90s and 2000s.
S.A.M. — Software Automatic Mouth (1982)

The first commercially available speech synthesizer, available for the Commodore 64, Atari, and Apple II. What makes SAM notable is that it exposed controls for pitch, speed, and inflection to the user. The company that made it later provided the technology underlying Macintosh’s Macintalk — which was the precursor to the say command.
Two Recurring Patterns
Before moving on, it’s worth noting two things that recur throughout this history.
Speaking machines are often demonstrated through singing. From HAL 9000 singing “Daisy Bell” in 2001: A Space Odyssey to Siri, singing has always been the ultimate proof-of-concept for TTS, because it forces the system to handle pitch variation, rhythm, and expressiveness. But there’s an implicit claim embedded in this: that singing is the pinnacle of human linguistic expression, and that a speaking machine isn’t truly “human” unless it can sing.


Speaking machines encode the biases of the culture that produces them. Faber put a female face on his Euphonia to make it seem less threatening. The Voderettes trained for years and are now forgotten. Most AI assistants today are female-coded by default. This isn’t incidental — it reflects a consistent pattern in how we try to make machines seem approachable by feminizing them, while making the actual human labor behind them invisible.
Macintalk and the say Command
In 1984, Apple shipped Macintalk, a formant-based TTS system. At its launch, Steve Jobs had the Mac introduce itself — a demo that was received with the kind of collective rapture that, in retrospect, feels a little embarrassing.
If you had an Apple computer in the ’90s, you probably remember playing with voices like Bad News, Cellos, Bubbles, Whisper, or Princess. In 2001, with Mac OS X (Cheetah), Apple added a command-line interface to this capability:

say -v Fred "I sure like being inside this fancy computer"
What most people don’t know is that say (and the underlying speech framework) had a hidden, low-level DSL for controlling prosody at the phoneme level. Here’s what it looks like:
[[inpt TUNE]]
~
AA {D 120; P 176.9:0 171.4:22 161.7:61}
r {D 60; P 166.7:0}
~
y {D 210; P 161.0:0}
UW {D 70; P 178.5:0}
_
S {D 290; P 173.3:0 178.2:8 184.9:19 222.9:81}
...
[[inpt TEXT]]
Each phoneme can be assigned a duration (D, in milliseconds) and a pitch curve (P, as frequency-at-position pairs). That chunk above is roughly “are you brushing your teeth?” decomposed into its constituent sounds and then recomposed with explicit timing and pitch. You can get surprisingly expressive with it — not natural-sounding, but expressive in a different way.
I couldn’t find many examples of other people using this syntax. It was documented on an archived Apple developer site and is now deprecated, removed from current macOS. (Which is why I needed to bring an old Mac mini to the demo.)
SaySynth
The idea behind saysynth is simple: if you can specify pitch per-phoneme in the say DSL, you can use it as a synthesizer. Instead of trying to produce legible speech, you push the tool in a direction it was never designed for.
Rather than writing raw DSL by hand, I built a YAML-based sequencer on top of it. Here’s an excerpt from a piece called “fire”:
name: fire
globals:
start_bpm: 65
rate: 160
stereo: true
tracks:
water:
type: chord
options:
root: F#2
text: wawer
voice: Victoria
chord_notes: [-12, -5, 0, 4, 9, 14]
segment_count: 1/32
randomize_segments: octaves,velocity
volume_range: [0.01, 0.19]
fire:
type: chord
options:
root: F#0
chord_notes: [0, 12]
text: fire!
segment_count: 1/6
randomize_segments: octaves,velocity
volume_range: [0.05, 0.4]
Each “chord” is produced by spawning multiple parallel say subprocesses, one per note. Because there’s no way to synchronize them precisely, they slowly drift in and out of phase. The system failing to do the thing it’s supposed to do is what makes it sound interesting — more organic, more human-like than it has any right to be.
I’ve also been working on support for alternative tunings via Ableton’s Scala (.ascl) format, which makes it possible to play in, say, Wendy Carlos’s tuning from Beauty in the Beast rather than standard 12-tone equal temperament.
Why Does This Matter?
Whatever you now find weird, ugly, uncomfortable and nasty about a new medium will surely become its signature… It’s the sound of failure: so much modern art is the sound of things going out of control, of a medium pushing to its limits and breaking apart.
— Brian Eno
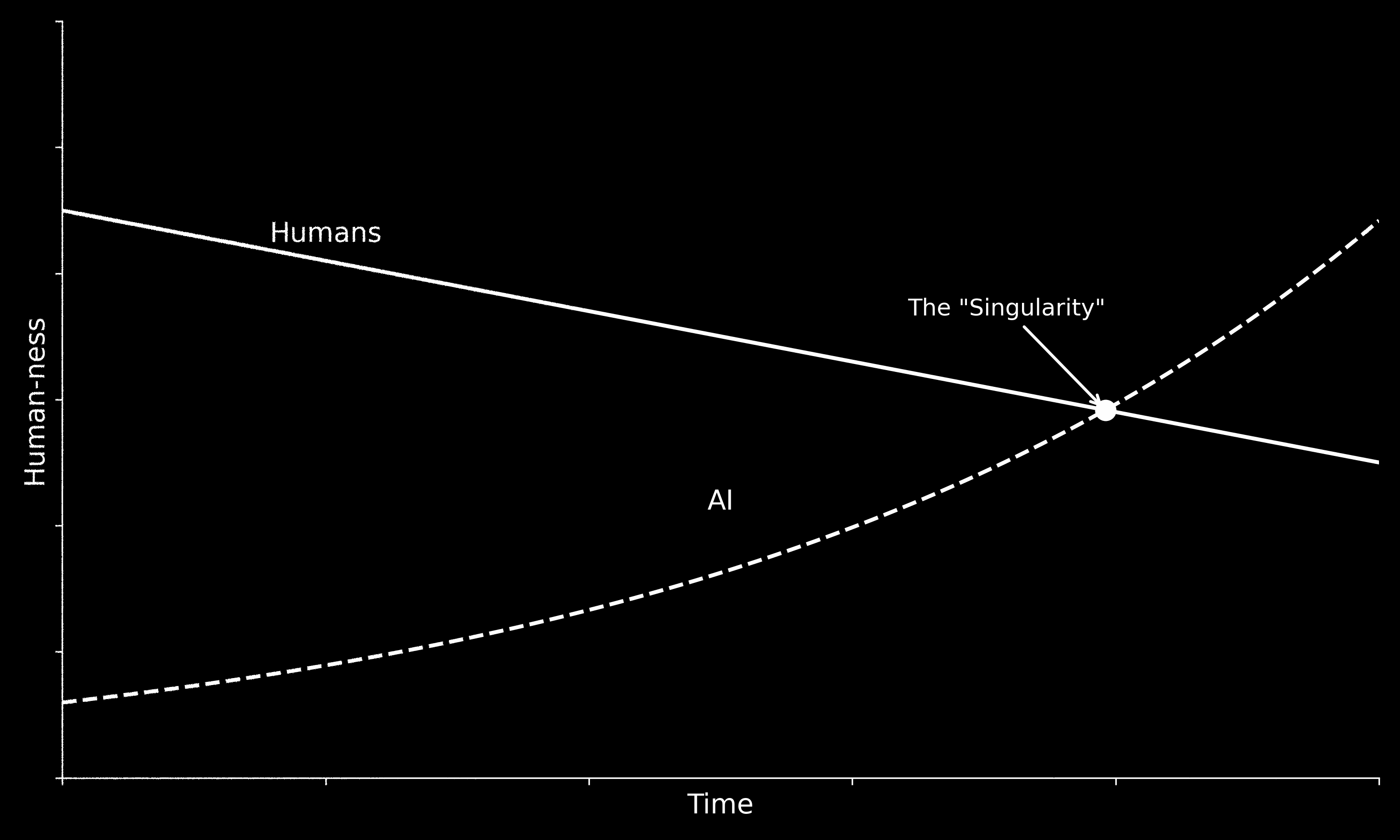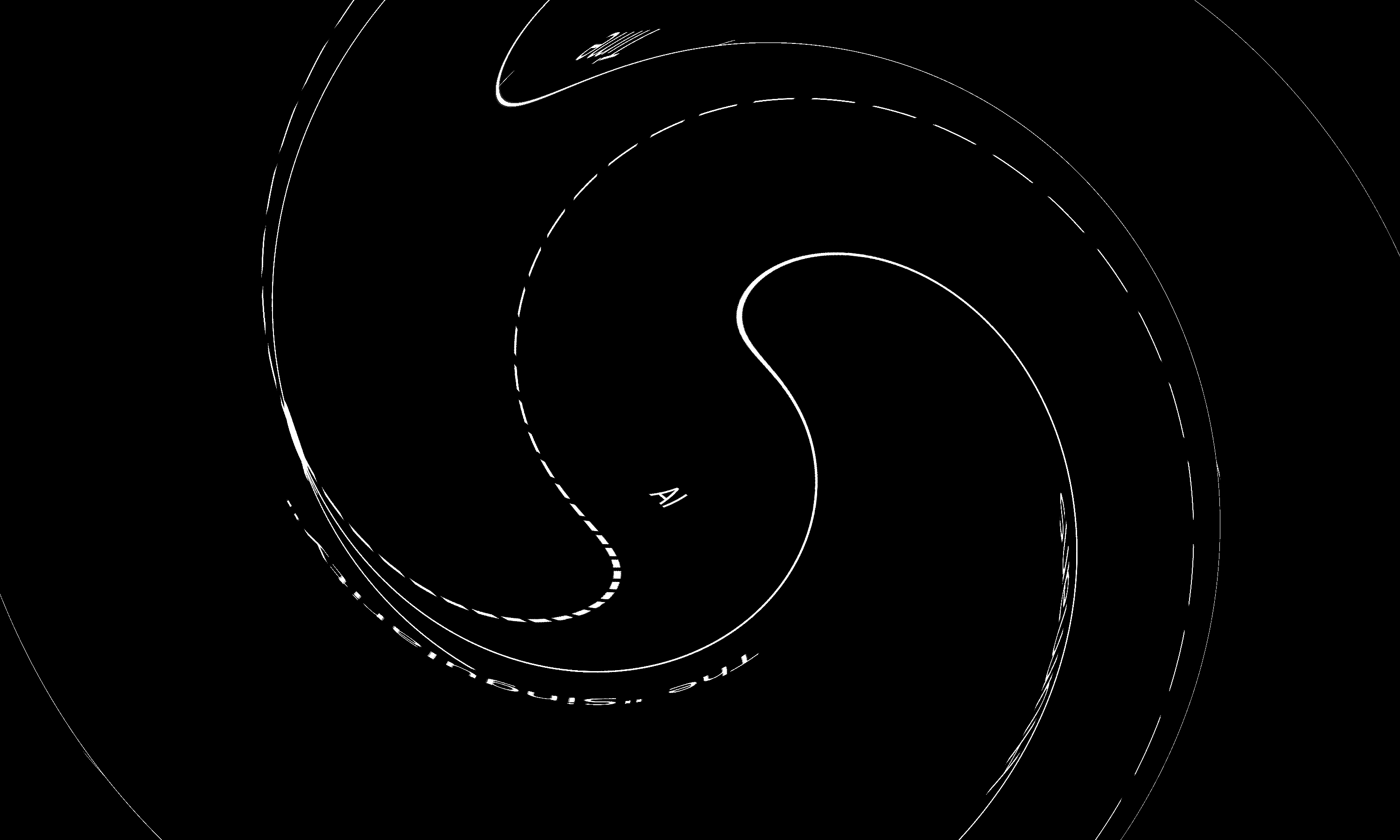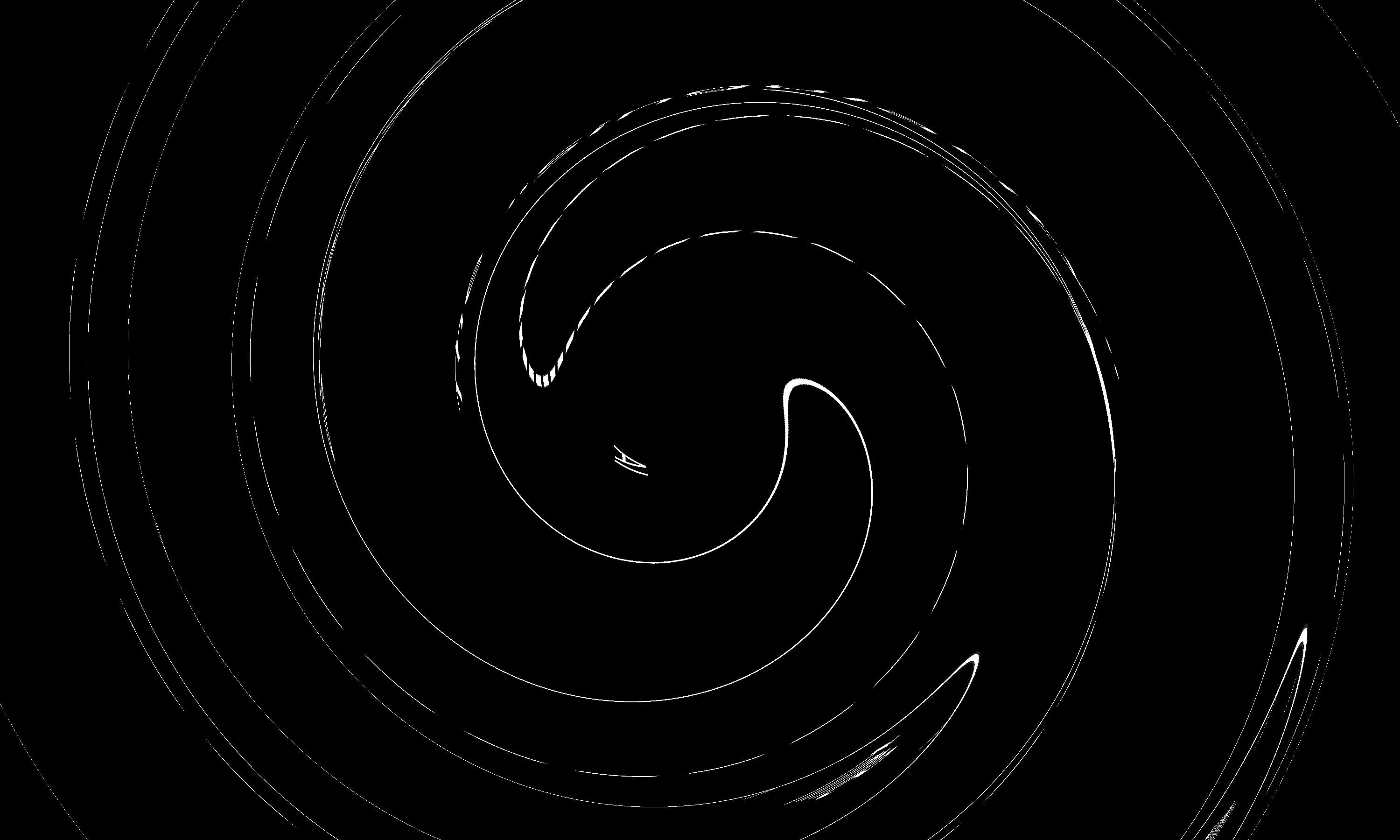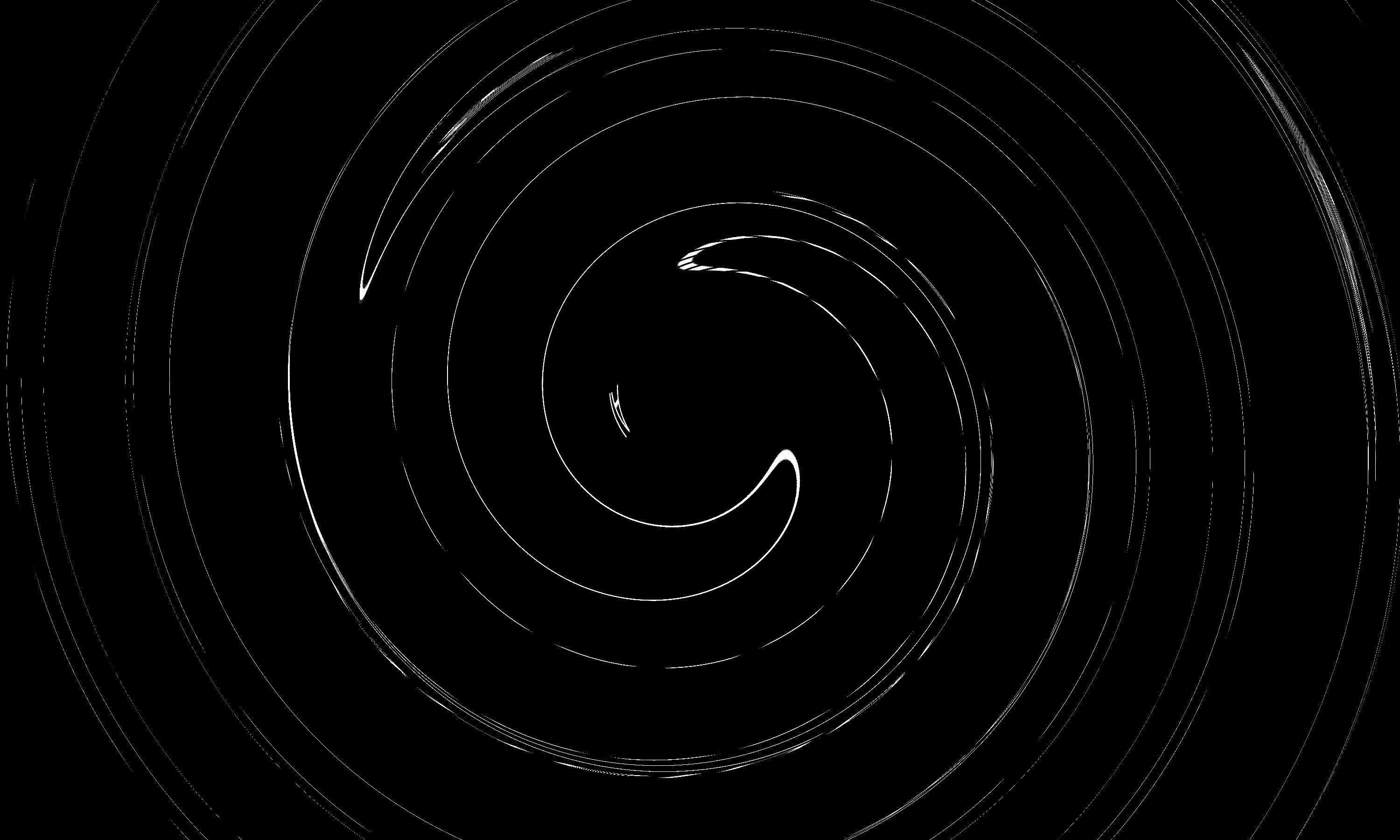
The version of the future that tech companies sell us is one in which AI improves exponentially until it reaches “humanness” — the singularity.
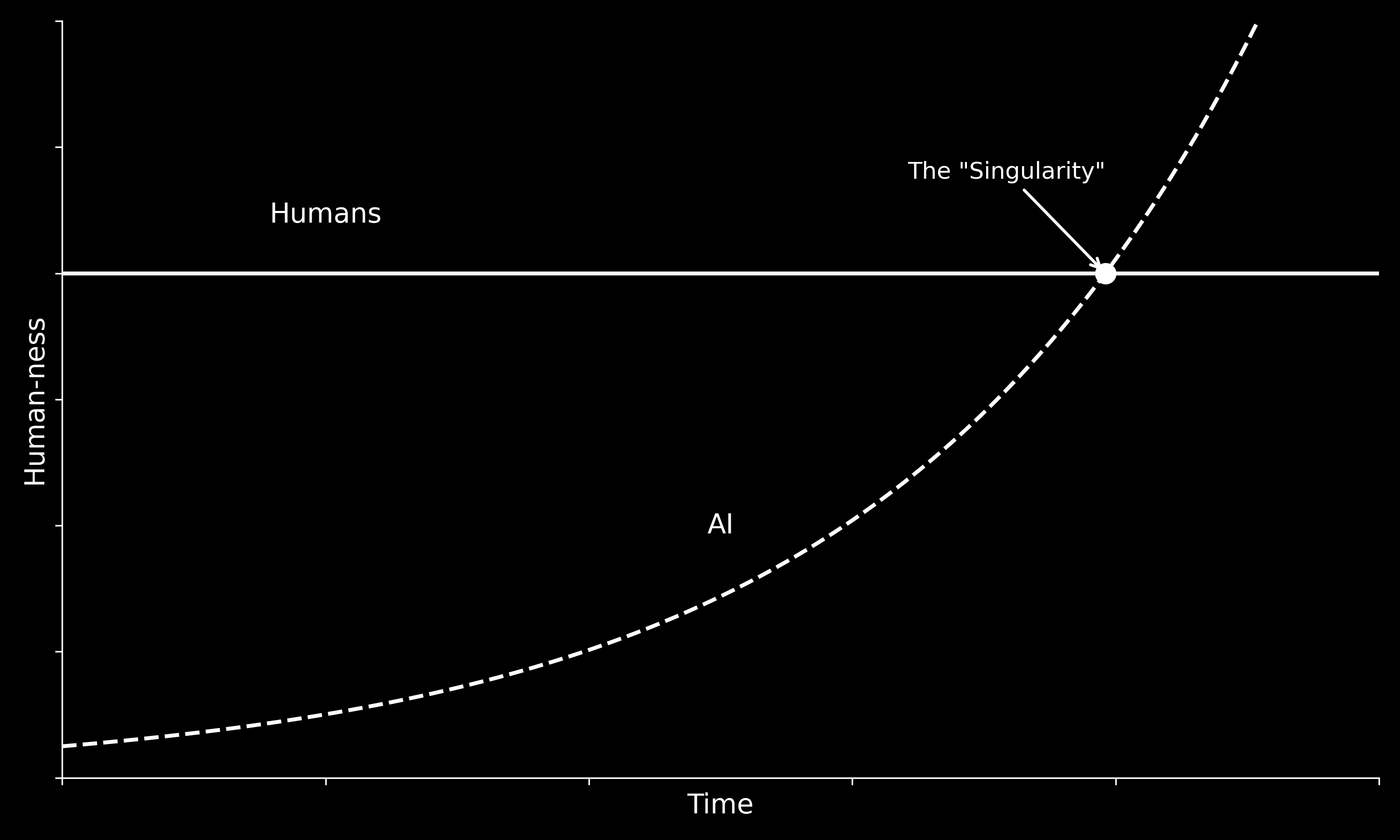
What this story leaves out is that humanness isn’t a fixed target. Capitalism slowly dehumanizes people, narrows what we do and how we’re valued, until it becomes easier for AI to approximate what we’ve become. If you’re training machine learning models, working in a distribution center, or running the same script as a telemarketer, you’re already being forced to function like a machine in the relevant sense.
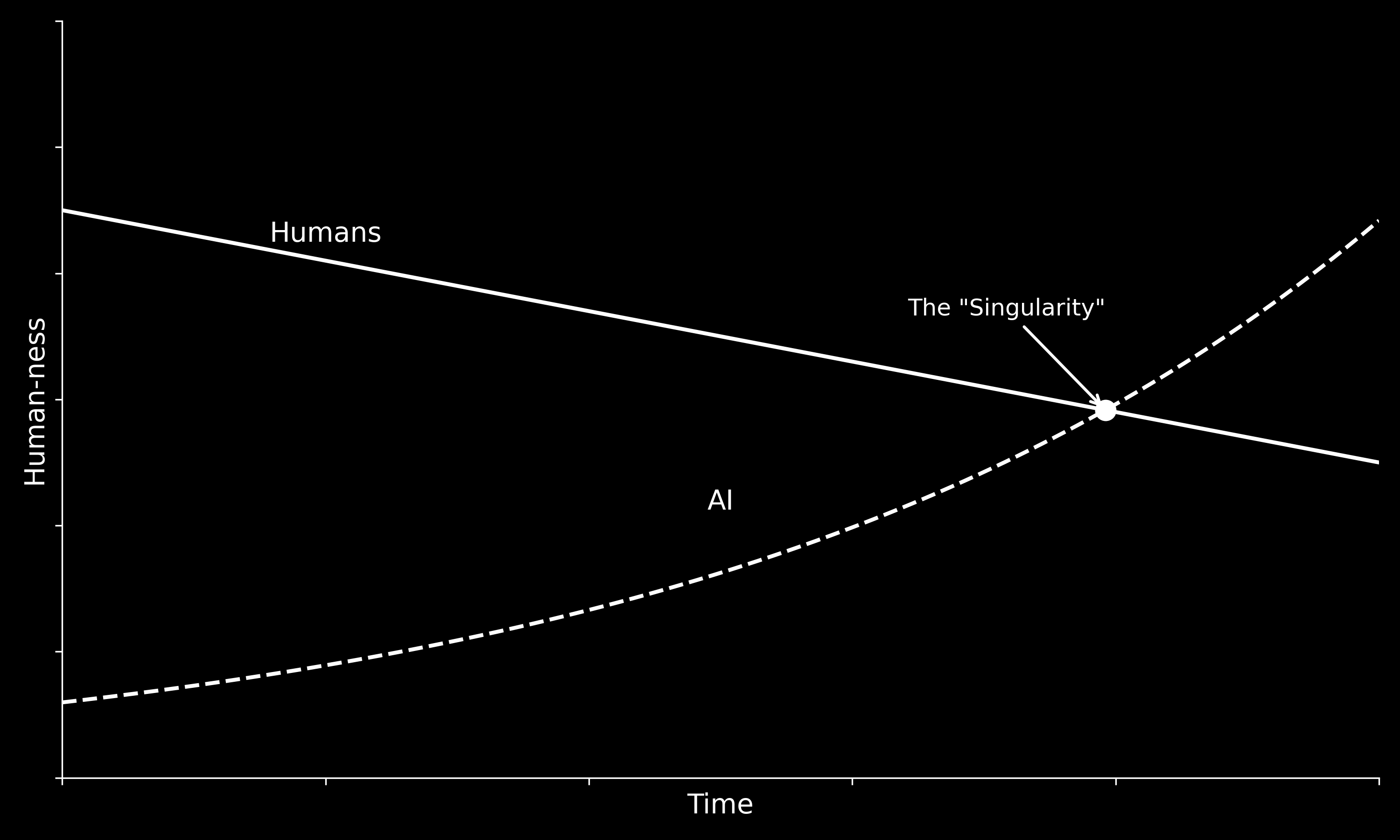
The history of speaking machines is, in part, a history of compressing the expressive range of human voice until it becomes usable — legible, predictable, efficient. Each generation of TTS gets more natural-sounding and less weird. The say command’s low-level phoneme DSL, which let you do genuinely strange things with pitch and timing, is now deprecated. SSML (the standardized modern alternative) lets you specify relative pitch but not actual frequencies. As TTS has gotten better at sounding human, it’s gotten less interesting as a creative tool.
I think there’s real value in working with tools that are supposed to do one thing and fail, tools that preserve the texture of their own limitation. Not for nostalgia’s sake, but because that texture is the thing — because art’s job right now might be to make strange what capitalism is trying to make invisible and ordinary.
Links in this post:
- "composition.codes": https://composition.codes/
- "Slides here": https://brian.abelson.live/slides/saysynth.html
- "Video here": https://www.youtube.com/watch?v=tX3nEPt0fKk
- "saysynth": https://gitlab.com/abelsonlive/saysynth
- "saysynth by Brian Abelson": https://abelsonlive.bandcamp.com/album/saysynth
- "been working on support for alternative tunings via Ableton’s Scala": https://gitlab.com/abelsonlive/asclpy